The VnPersonSearch3000 Dataset
The 3000VnPersonSearch dataset includes pairs of image and description. The images are person bounding boxes that are extracted from video frames. The videos are captured by both moving cameras and fixed-position cameras with different fields of view. They are captured during day and night time with street lamp light. The capture scenarios are mostly crowded street and outdoor festival scenes, so the occlusion and pose variance also appearData collection for 3000VnPersonSearch
In our previous work [33], human bounding boxes are manually extracted and wellbounded boxes are chosen for image database. This is a tedious task and far from realworld scenarios. In this work, we propose to perform this task via semi-automatic way. Firstly, the YOLO-v4 method [1] is applied to automatically detect human in each frame. The DEEPSORT tracking method presented in [52] is then utilized to track detected persons over time. Figure 1 shows examples of detection and tracking results.

Fig 1. Examples of human detection and tracking sequences. The red bounding boxes contain the images
that are chosen for person search dataset
As our objective is not to evaluate detection and tracking models, so we just take the output of the detector and tracker to build our dataset. As the detector and tracker could be imperfect, we manually check and remove false positives or poor samples (too small resolution, motion blur, highly occluded..). We also check to correctly cluster the person images that belong to the same ID. By this way, we collect the person images for 3000 IDs and each ID has more than two images with front and back/side views. To be able to widely release the new built dataset for research purposes while still ensure person privacy, all face areas of persons in the dataset are blurred. To this end, we apply the face detection in the dlib library [16] to extract face regions and then blur these regions by an ellipse with 10% transparency. Moreover, to facilitate the description process of person images, a web-based interface is built for the descriptors. Figure 2 shows the interface of our website by which the users can log into it to make a new description or edit the existing ones for a person image.
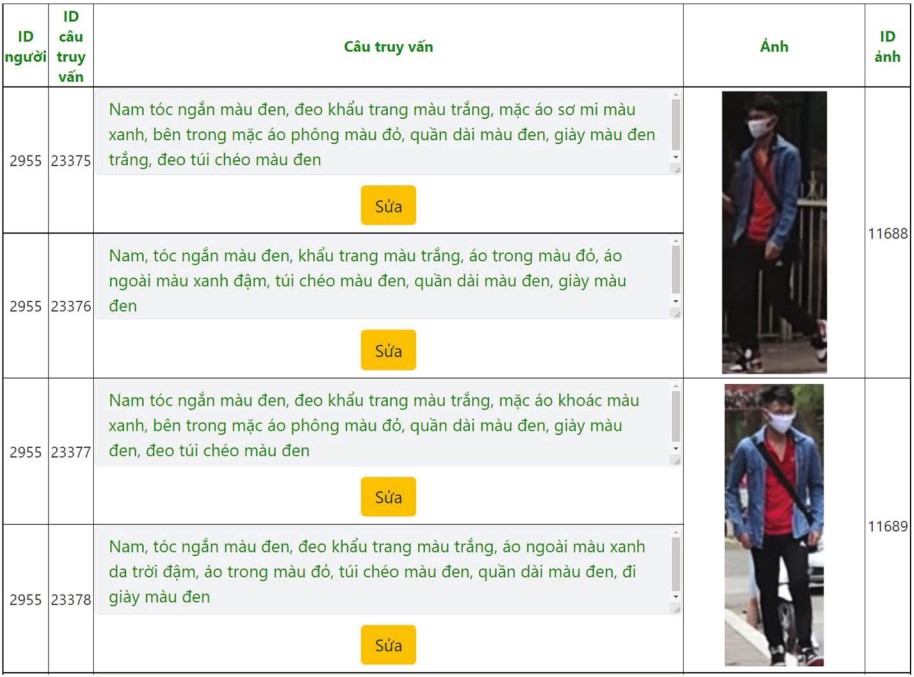
Fig 2. The annotation GUI for Vietnamese language-based person search
The interface is laid out with person images, descriptions, together with the corresponding person IDs. Thanks to the developed interface, the descriptions for person images are made by ten subjects to ensure the diversity of the descriptive language sentences. Each image is described by two different subjects. There are 6,302 person images with 12,602 Vietnamese descriptions in total. Figure 3 shows some example IDs with images and the corresponding Vietnamese descriptions in 3000VnPersonSearch datataset.
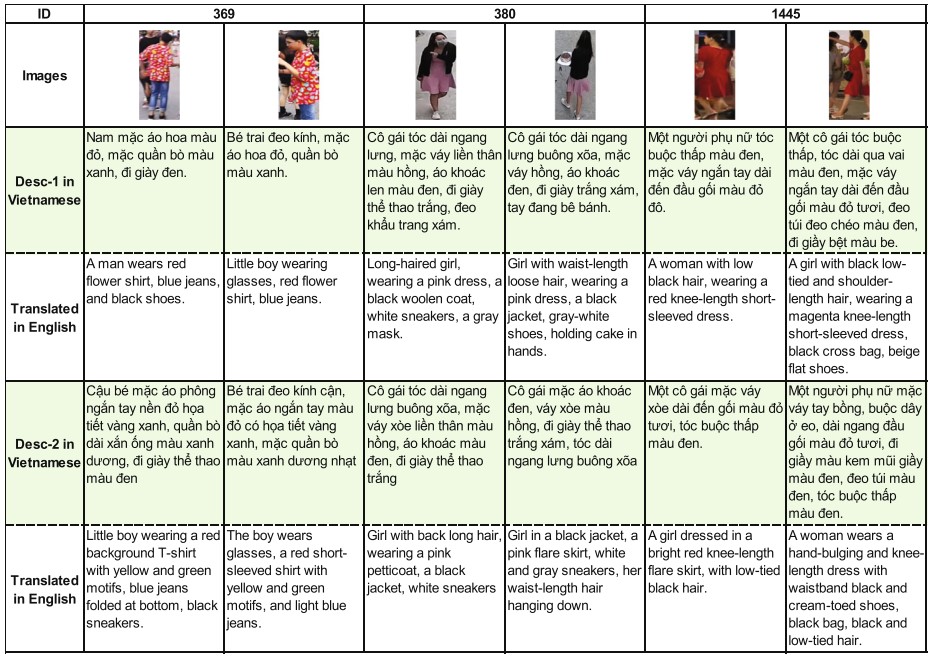
Fig 3. Examples of images and Vietnamese descriptions of three persons/IDs (369, 388 and 1445) in
3000VnPersonSearch dataset. Each person/ID has two images and each image has two descriptions (Desc-1
and Desc-2)
Vietnamese text pre-processing in 3000VnPersonSearch
Vietnamese is an isolating language in which the basic unit is syllable. In writing, syllables are separated by a white space. One word corresponds to one or more syllables. Almost vocabulary is created by two or more syllables (80% of words are bi-syllable). For example a Vietnamese sentence of “Một người đan ` ong m ˆ ặc ao kho ´ ac m ´ au ` đen” (in English: a man wears a black coat) contains 9 syllables that are segmented into 5 words as follows “một (one) người đan ` ong (man) m ˆ ặc (wear) ao ´ khoac (a coat) m ´ au ` đen (black)”. These segmented units are words and also called tokens. We use the underscore symbol “ ” to concatenate syllables into a word. Therefore we can keep the space as the separator for word. There are several popular word segmentation tools for Vietnamese such as JVnSegmenter, vnTokenizer, UETsegmenter. In this paper, Vietnamese text is all segmented into words using RDRsegmenter tool which is reported to be superior to other tools at this moment in both accuracy and performance speed. The current accuracy of the RDRsegmenter on a set of two thousand testing sentences is about 97.90% F1 score [30]. The main error of word segmentation is ambiguity error. For example: the sequence of words “dep t ´ ong ˆ đỏ” can be segmented as “dep t ´ ong ˆ đỏ” (sandals with red color tone) or “dep ´ tong ˆ đỏ” (red flip-flops). In 3000VnPersonSearch, there are a total of 6,302 person images with 12,602 Vietnamese descriptions. Each description can be one or more sentences. The average length of the descriptions is 30.02 tokens, the longest one contains 95 tokens and the shortest one has 7 tokens (see Fig. 4). There are 1,827 unique tokens with a total of 378,274 occurrences in the dataset
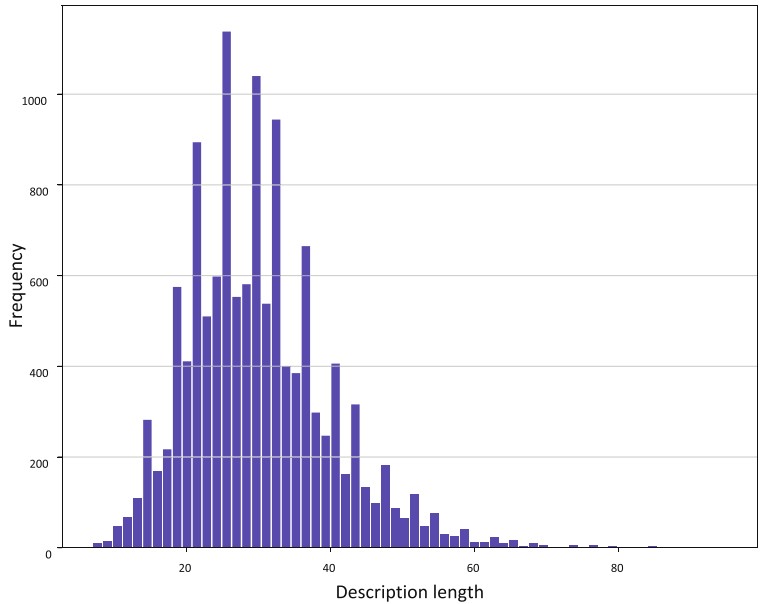
Fig 4. Frequency of description length in word/token for 3000VnPersonSearch dataset: the total number of
descriptions is 12,602; the average length is 30.02 tokens with the standard deviation in length is 9.91; the
longest description is 95 tokens and the shortest is 7 tokens
Main challenges of 3000VnPersonSearch
Table 1 shows the statistics of our 3000VnPersonSearch dataset in comparison with the CUHK-PEDES dataset (the unique data set for person search based on English description) and our previous data set VnPersonSearch created in [33].
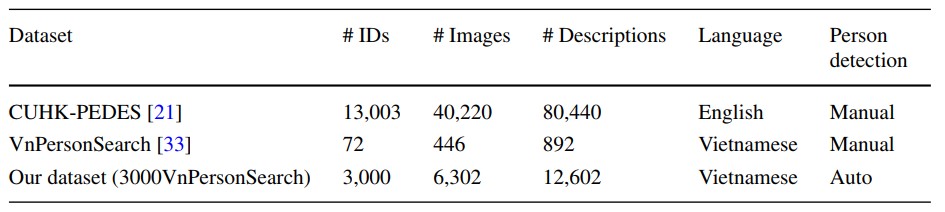
Table1. Comparison of text-based person search datasets
Although the number of IDs in 3000VnPersonSearch data set is smaller than that in the CUHK-PEDES dataset, the 3000VnPersonSearch dataset raises some challenges that reflect the real scenarios: (1) It contains some detected person images that do not fully show the human from head to toe. This caused by occlusion or poor detection phase (see example images of ID 369 in Fig. 4); (2) The same person may bring belongings or not when captured at different tracks (for example, the same girl with the ID 380 in Fig. 3 brings nothing when she comes in a baker but when return she holds a cake in hands. These images are captured at different tracks); (3) Different camera viewpoint angles capture the same person with or without belongings (for the same girl of the ID 1445 in Fig. 4, at a side view, we see a black cross bag worn, but at backside capture this bag is not shown); (4) Depending on the expression of the subjects, the same objects can be described differently (for the ID 369 descriptions, one subject used “red flower shirt” but the other one describes “red background T-shirt with yellow and green motifs”.) (5) The Vietnamese language is one of the most rich of vocabulary and expression languages in the world, so Vietnamese descriptions are diverse and abundance.
To leverage the new dataset for research community, 3000VnPersonSearch dataset is organized in the same format as CUHK-PEDES and is available for research purpose upon request.
Terms & Conditions of Use
The datasets are released for academic research only, and are free to researchers from educational or research institutes for non-commercial purposes.
Related Publications
All publications using 3000VnPersonSearch or any of the derived datasets should cite the following papers:
- Pham, Thi Thanh Thuy, Hong-Quan Nguyen, Hoai Phan, Thi-Ngoc-Diep Do, Thuy-Binh Nguyen, Thanh-Hai Tran, and Thi-Lan Le. "Towards a large-scale person search by vietnamese natural language: dataset and methods. Multimedia Tools and Applications 81, no. 19 (2022): 27569-27600.
Download
The requestor must sign in the commitment and send it to the database administrator (lan.lethi1@hust.edu.vn) by email.