StudentAct Dataset
The StudentAct dataset is meant to aid research efforts in the general area of developing, testing and evaluating algorithms for human activity recognition. The Hanoi University of Science and Technology (HUST) has copyright in the collection of activity video and associated data and serves as a distributor of the StudentAct dataset.
Release of the Database To advance the state-of-the-art in activity recognition, this database could be downloaded here. The requestor must sign in the commitment and send it to the database administrator (lan.lethi1@hust.edu.vn) by email. In addition to other possible remedies, failure to observe these restrictions may result in access being denied for the database.
The researcher(s) agrees to the following restrictions on the StudentAct dataset:
- Redistribution: Without prior written approval from the database administrator, the StudentAct dataset, in whole or in part, will not be further distributed, published, copied, or disseminated in any way or form whatsoever, whether for profit or not. This includes further distributing, copying or disseminating to a different facility or organizational unit in the requesting university, organization, or company.
- Modification and Commercial Use: The StudentAct dataset, in whole or in part, may not be modified or used for commercial purposes.
- Publication Requirements: In no case should the still frames or video be used in any way that could cause the original subject embarrassment or mental anguish.
- Citation/Reference: All documents and papers that report on research that uses the StudentAct dataset will acknowledge the use of the database by including an appropriate citation to the following StudentAct dataset. Phuong-Dung Nguyen, Hong-Quan Nguyen, Thuy-Binh Nguyen, Thi-Lan Le, Thanh-Hai Tran, Hai Vu, Quynh Nguyen Huu, A new dataset and systematic evaluation of deep learning models for student activity recognition from classroom videos, 2022 International Conference on Multimedia Analysis and Pattern Recognition (MAPR)
Details
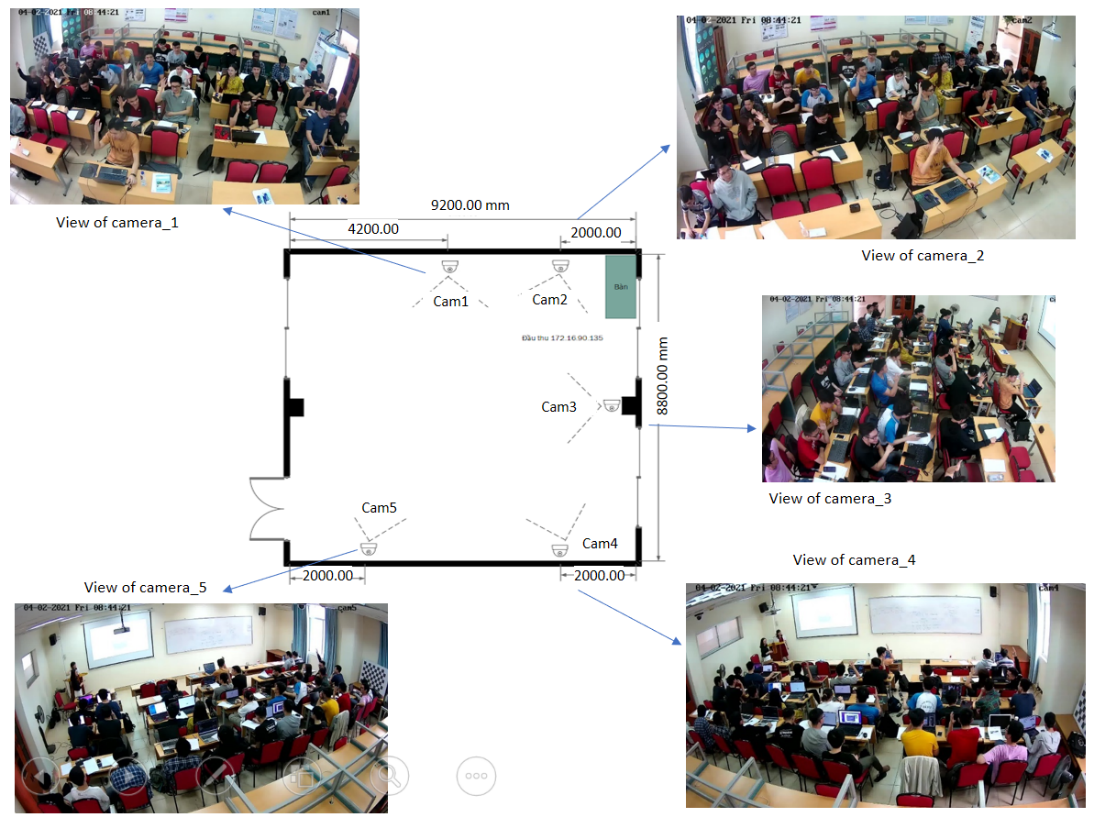
The data was collected from classes with different subjects and numbers of students, at the meeting room on the 9th floor of B1 building, Hanoi University of Science and Technology. The classroom measures 9.2m x 8.3m x 3.5m, can accommodate about 60 students, and is equipped with 5 cameras at 5 different viewing angles to ensure accurate images of activities and minimize obstruction. This data can also be used for multi-angle detection and recognition problems. The cameras are set to record at a speed of 25fps, with a resolution of full HD 1920x1080 pixels, and are synchronized in terms of recording time. In addition, the camera has a cover to help teachers and students feel as natural as possible, without feeling watched. Figure 1 shows the camera setting for data collection:
After recording, 45 GB of videos have been collected. We split the videos into frames at 5fps, and labeled all simultaneous activities in each frame. This approach reduces redundancy while retaining necessary information. We used an improved version of the LabelMe labeling tool to label at a fast speed and high accuracy. After labeling 31,046 images, we obtained a set of 596,371 bounding boxes for 5 activities of interest. The activities are named in English as follows: sitting, raising_hand, standing, sleeping, and using_phone.
The labeled data is stored in json files, each with a corresponding image folder. The data format stored in the json file is described as follows:
{"images":[{"file_name":"….jpg","width":1920,"height":1080,"id":…},…],
"categories":[{"id":0,"name":"head"},
{"id":1,"name":"sitting"},
{"id":2,"name":"standing"},
{"id":3,"name":"raising_hand"},
{"id":4,"name":"using_phone"},
{"id":5,"name":"sleeping"}],
"annotations":[{"bbox":[top, left, width, height], "category_id":…, "image_id":…, "iscrowd":0, "area":…, "person_id":…,"cam_id":…,"id":…}, …]}
- “images”: contains a list of image file names, the size of the image files, and the id of those files. The image file name is formatted as [camera_name][yearmonthdayhourminutesecond]_[sequence_number_starting_from_starttime]. For example: ch01_20210331111112_0001.jpg => image number 0001 from 11:11:12 on 31/03/2021 viewed from camera 1.
- “categories”: contains a list of label
- “annotations”: contains a list of label definitions, each definition includes: the top-left coordinates of the bounding box of the label, the size of the bounding box, label id (corresponding to the categories list), image id (corresponding to the images list), area of the label region, student id, camera id, and that label’s id.